Analytic¶
เป็นเครื่องมือที่ใช้สำหรับทำการวิเคราะห์ข้อมูลในเชิงลึก ใช้ในการคาดการณ์เหตุการณ์ที่อาจจะเกิดขึ้นอนาคต จากข้อมูลที่เกิดขึ้นอดีต (Data Analytics) ซึ่งซอฟต์แวร์ที่มีให้ใช้ในปัจจุบัน คือ Jupyter Notebook
Library ที่จำเป็นที่ใช้ในการวิเคราะห์ข้อมูล¶
Pandas เป็น library ที่มีจุดเด่นคือใช้ในการวิเคราะห์ข้อมูล โดยที่ Pandas สามารถอ่านไฟล์ได้เกือบทั้งหมด และ Pandas ยังมีคำสั่งที่จะช่วยเตรียมข้อมูลให้สมบูรณ์ก่อนที่จะนำไปคำนวณได้ จึงเป็น Library ที่ใช้ในด้าน Data Science ได้
Numpy คือ library ที่เกี่ยวกับฟังก์ชั่นทางคณิตศาสตร์และการคำนวณต่างๆ โดยจะเข้าไปจัดการข้อมูลที่เป็นตารางแบบ array
Matplotlib เป็น library ที่ใช้ในการสร้างกราฟจาก array ซึ่งสามารถสร้างกราฟได้ทั้งในเเบบ 2 มิติ , 3 มิติ, กราฟเส้นตรง, พาราโบลา และกราฟอื่นๆได้อีกมากมาย แต่ทั้งนี้การที่มันจะทำงานได้ ต้องมีการใช้ควบคู่ไปกับ numpy
Seaborn เป็น library เหมือนกับ Matplotlib แต่จะมีการพล็อตกราฟที่สวยขึ้น ถูกพัฒนาขึ้นมาจาก Matplotlib
Scikit-learn (sklearn) เป็น library ทีใช้ในการทำ Machine Learning ซึ่ง Scikit-learn มี code ที่สามารถจัดการข้อมูลได้หลากหลาย ไม่ว่าจะเป็นการทำ Clustering , Classification , regression ซึ่งในที่นี้จะให้คอมพิวเตอร์เรียนรู้แบบ linear regression เเละยังสามารถนำมาประยุกต์ใช้กับ Data Science ได้
การสร้างไฟล์¶
เริ่มแรกให้ทำการสร้างไฟล์ขึ้นมาก่อนโดยทำการคลิกที่ปุ่ม "file" เลือกไปที่ "new" และเลือก "notebook"
จากนั้นทำการคลิกเข้าไปจะมีหน้าต่าง Select kernel เลือก Python3(ipykernel) แล้วกด "Select"
จะได้ไฟล์ขึ้นมาดังรูป
การใช้งาน jupyternotebook เบื้องต้น¶
ใน Jupyter notebook จะทำงานร่วมกับ Cell ซึ่ง Cell เป็นได้ 3 อย่างดังนี้
Code เป็น block ของ code(python) เราสามารถกด Enter ได้จะเป็นการขึ้นบรรทัดใหม่ ใน 1 cell มี code ได้หลายบรรทัด
Markdown เป็นการเขียน markdown เพื่อให้คำอธิบายเพิ่มเติม อาจเป็น link ไปยัง reference site ภายนอก หรือแสดงรูปภาพ Markdown
Raw เป็นข้อความหรือคำอธิบายที่เป็น text ธรรมดา
ในส่วนการ run jupyter notebook สามารถเลือกกด run ทีละ cell หรือ run ทั้งไฟล์(ทุก cells) เลยก็ได้

เป็นการ run cell ที่ถูกเลือก

เป็นการ run cells ทั้งหมดที่อยู่ในไฟล์
ในแต่ละ cell จะมีเครื่องมือที่ช่วยในการจัดการ cell ได้

Duplicate ปุ่มแรกจะเป็นการสร้าง cell ที่เหมือนกันขึ้นมาอีก cell
Move Up กดปุ่มลูกศรขึ้นจะเป็นการสลับที่กับ cell ก่อนหน้า
Move Down กดปุ่มลูกศรลงจะเป็นการสลับที่กับ cell ถัดไป
Insert Above จะเป็นการเพิ่ม cell ก่อนหน้า
Insert Below จะเป็นการเพิ่ม cell ถัดจาก cell ปัจจุบัน
Delete ลบ cell ออก
การใช้งาน jupyternotebook ร่วมกับ InfluxDB¶
ตัวอย่าง
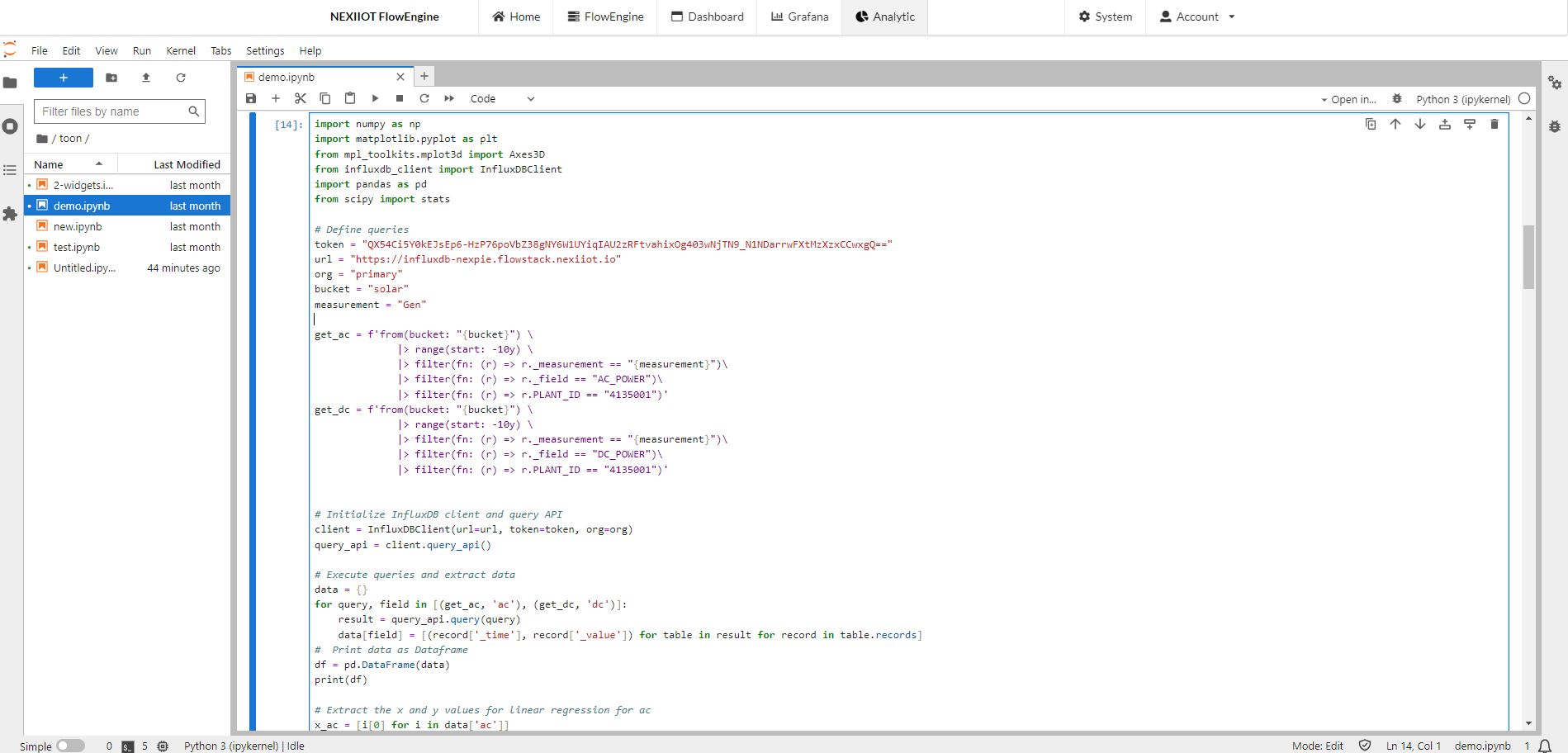
ตัวอย่างการใช้งานจะเป็นการดึงค่าจาก InfluxDB โดยจะเป็นการดึงค่ากระแสและแรงดันไฟฟ้าเพื่อนำมาวิเคราะห์ข้อมูลและพล็อตออกมาเป็นกราฟ
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from influxdb_client import InfluxDBClient
import pandas as pd
from scipy import stats
# Define queries
token = "QX54Ci5Y0kEJsEp6-HzP76poVbZ38gNY6W1UYiqIAU2zRFtvahixOg403wNjTN9_N1NDarrwFXtMzXzxCCwxgQ==" // เอามาจาก InfluxDB
url = "https://influxdb-nexpie.flowstack.nexiiot.io"
org = "primary" // คือ Organization
bucket = "solar" //คือ Bucket ที่ต้องการนำมาวิเคราะห์ข้อมูล
measurement = "Gen" // คือ Measurement ที่ต้องการนำมาวิเคราะห์ข้อมูล
get_ac = f'from(bucket: "{bucket}") \
|> range(start: -10y) \
|> filter(fn: (r) => r._measurement == "{measurement}")\
|> filter(fn: (r) => r._field == "AC_POWER")\
|> filter(fn: (r) => r.PLANT_ID == "4135001")'
get_dc = f'from(bucket: "{bucket}") \
|> range(start: -10y) \
|> filter(fn: (r) => r._measurement == "{measurement}")\
|> filter(fn: (r) => r._field == "DC_POWER")\
|> filter(fn: (r) => r.PLANT_ID == "4135001")'
# Initialize InfluxDB client and query API
client = InfluxDBClient(url=url, token=token, org=org)
query_api = client.query_api()
# Execute queries and extract data
data = {}
for query, field in [(get_ac, 'ac'), (get_dc, 'dc')]:
result = query_api.query(query)
data[field] = [(record['_time'], record['_value']) for table in result for record in table.records]
# Print data as Dataframe
df = pd.DataFrame(data)
print(df)
# Extract the x and y values for linear regression for ac
x_ac = [i[0] for i in data['ac']]
y_ac = [i[1] for i in data['ac']]
# Extract the x and y values for linear regression for dc
x_dc = [i[0] for i in data['dc']]
y_dc = [i[1] for i in data['dc']]
เมื่อทำการใส่ code ข้างต้นแล้วทำการกด run จะได้ output ac และ dc ขึ้นมา
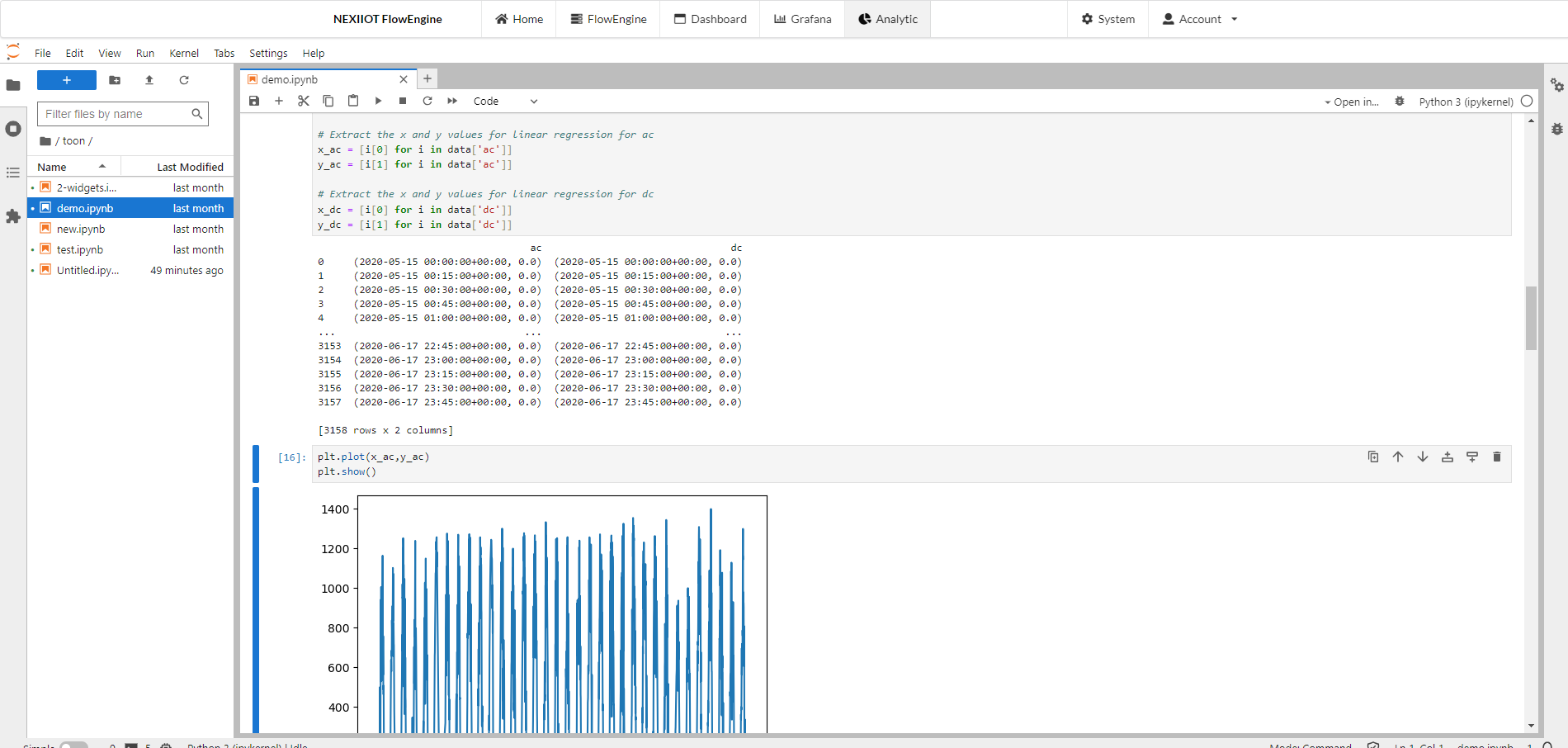
จากนั้นทำการพล็อตกราฟโดยใช้คำสั่ง
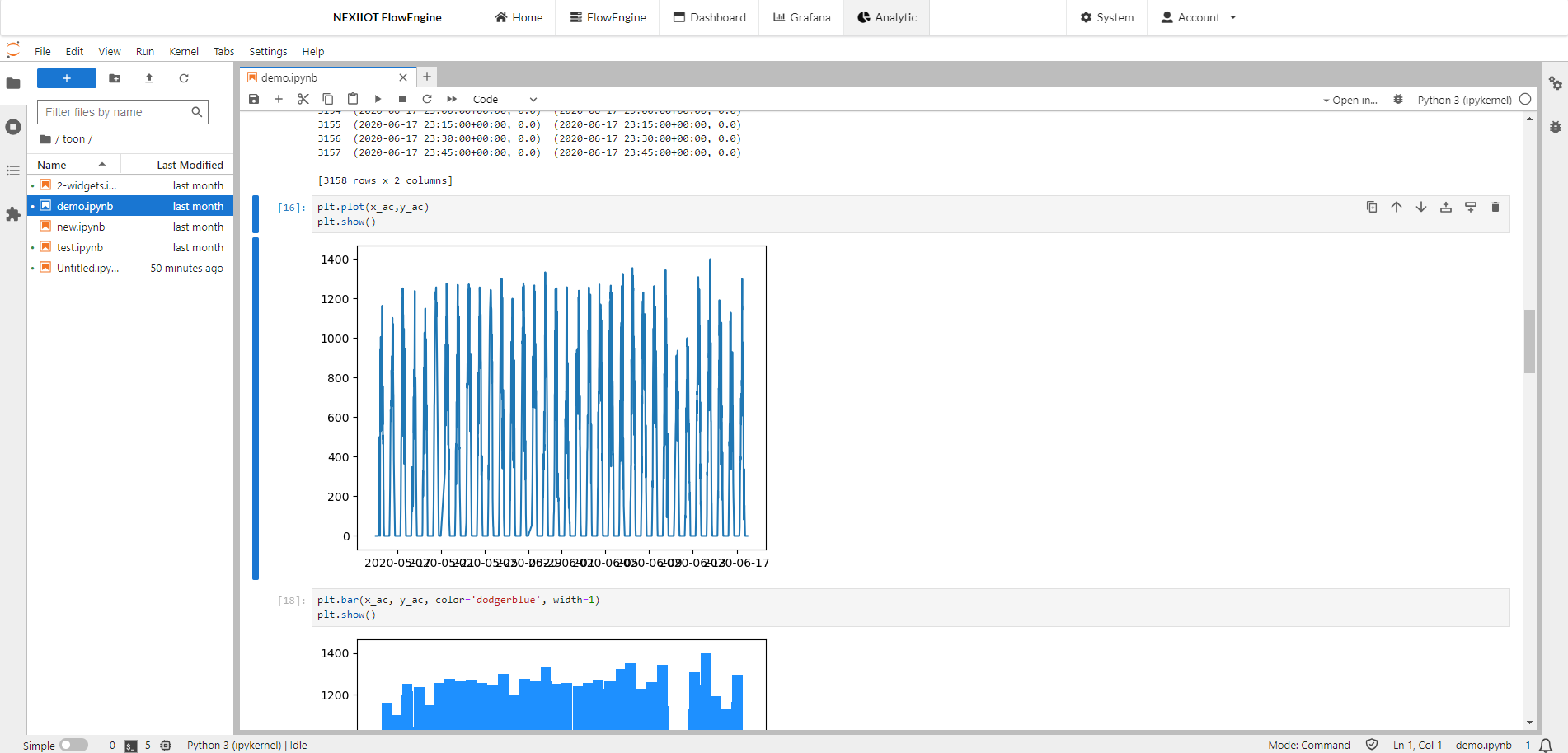
จะได้กราฟขึ้นดังรูป
Node Jupyter Cell¶
โหนด "Jupyter Cell" ทำหน้าที่ใช้ในการอ่านไฟล์จากส่วนของ Analytic และดำเนินการ execute โค้ดที่อยู่ไฟล์ดังกล่าว ซึ่งภายในไฟล์สามารถเขียนโค้ดแยกเป็นส่วนๆได้ (หรือเรียกว่า cell) นอกจากนี้ยังสามารถเลือก execute โค้ดแต่ละส่วนตามความต้องการของผู้ใช้ได้
วิธีการใช้งาน node jupyter cell
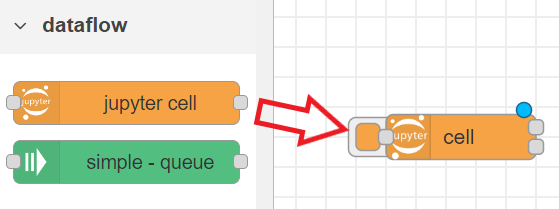
ให้ผู้ใช้งานลากโหนด "Jupyter Cell" ที่อยู่ในแพลิตต์ทางด้านซ้าย หมวดหมู่ device มาวางลงพื้นที่เวิร์คสเปซ ซึ่งแสดงดังรูป
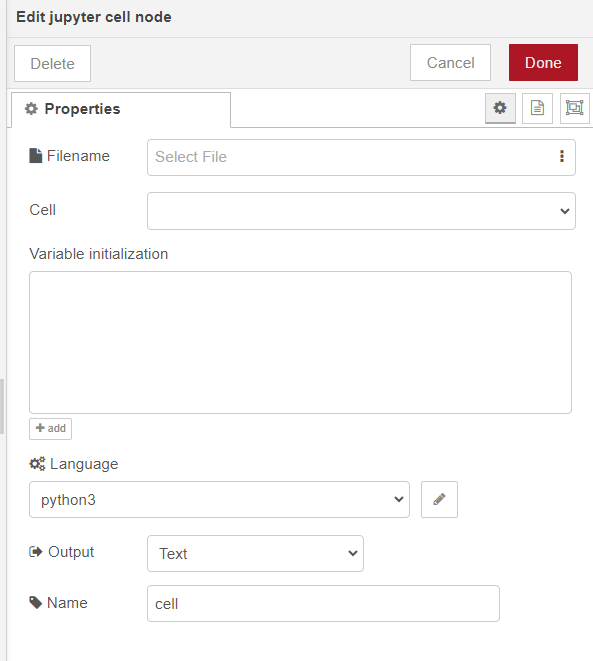
ทำการ double click ที่ตัวโหนด "Jupyter Cell" บนเวิร์คสเปซเพื่อเปิดหน้าต่างแก้ไขขึ้นมา หน้าต่างแก้ไขนี้ใช้ในการเลือกไฟล์ และเลือก language ที่ต้องการรัน ซึ่งแสดงดังรูป
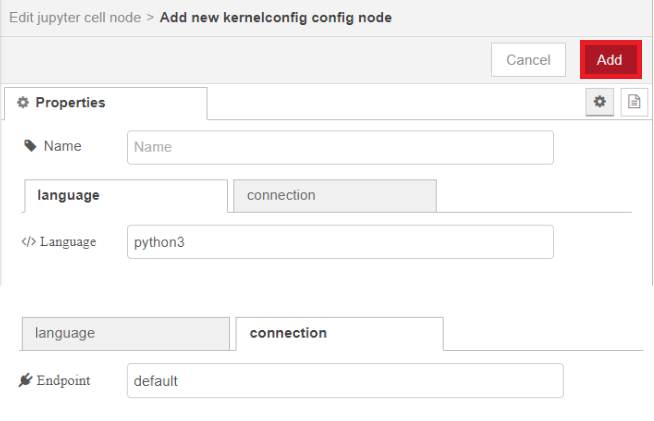
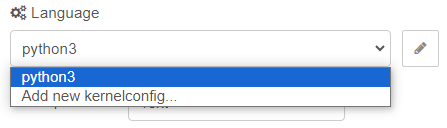
โดยผู้ใช้ต้องเลือก Language ที่จะใช้ในการรันโค้ด ซึ่งถ้ามีตัวเลือกเพียง "Add new kernelconfig…" หมายความว่า ผู้ใช้ยังไม่ได้สร้าง Language โดยผู้ใช้สามารถสร้าง Language ขึ้นมาได้โดยการเลือก "Add new kernelconfig…" และคลิกรูป icon ดินสอดังรูป

โดยจะขึ้นหน้าต่างให้กรอกรายละเอียดของ Language ที่ต้องการใช้ ซึ่งผู้ใช้สามารถกรอกรายละเอียดได้ดังนี้
Language ระบุภาษาที่ต้องการใช้ในการรัน โดยโหนดกำหนดค่าเริ่มต้นเป็น python3
ภาษา python: python3
ภาษา javascript: javascript
Endpoint ตำแหน่งของ Jupyter Notebook ที่ใช้ในการโต้ตอบ และจัดการข้อมูลกับ Flow Engine โดยโหนดกำหนดค่าเริ่มต้นเป็นเป็น default
เมื่อผู้ใช้เพิ่ม Language สำเร็จ โหนด "Jupyter Cell" เลือก Language ที่สร้างขึ้นให้อัตโนมัติ ซึ่งแสดงดังรูป
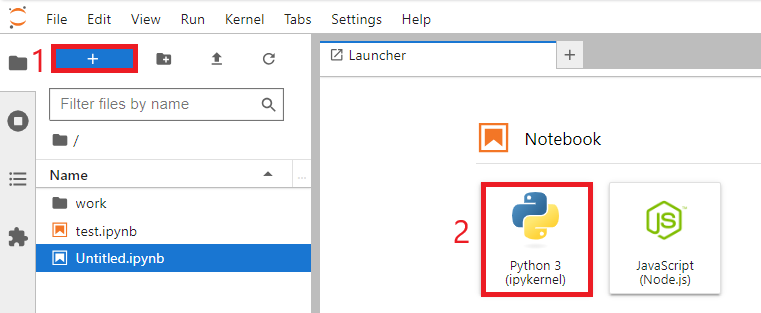
โหนด "Jupyter Cell" จะดำเนินการอ่านไฟล์ที่ส่วนของ Analytic และผู้ใช้สามารถเลือก cell ที่ต้องการจะให้ทำงานได้ โดยคลิกที่ Analytic หลังจากนั้นดำเนินการสร้างไฟล์ ซึ่งเมื่อคลิก Python3 (ipykernel) จะได้ไฟล์ชื่อ "Untitled.ipynb"
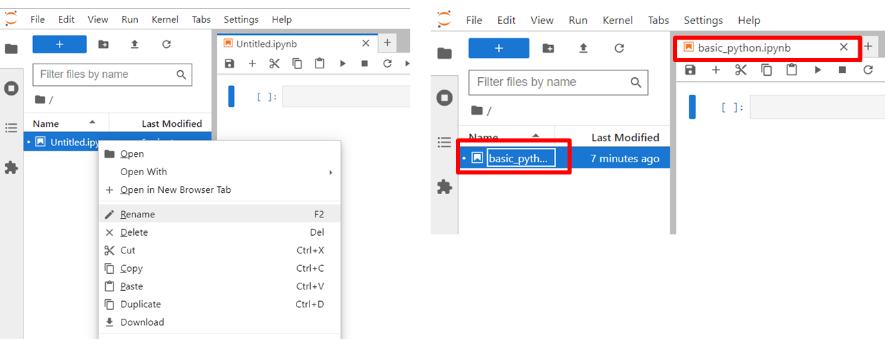
โดยผู้ใช้สามารถตั้งชื่อไฟล์ใหม่ได้ ด้วยการคลิกขวาที่ไฟล์ และเลือก Rename แสดงดังรูป
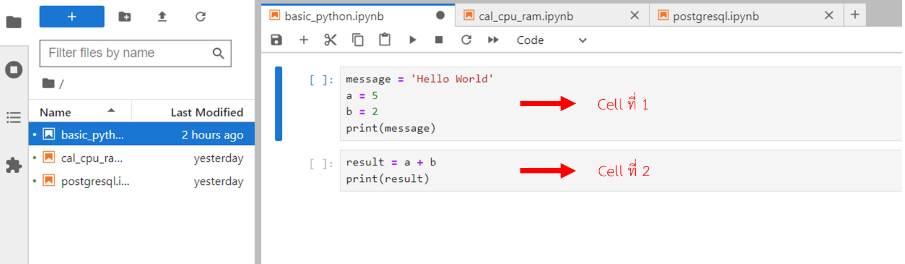
นอกจากนี้ผู้ใช้สามารถเขียนโค้ด python ลงใน cell หรือสร้าง cell ใหม่เพิ่มขึ้นมา เพื่อแยกโค้ด python ตามที่ต้องการได้ ตัวอย่างการเขียน Code ประกาศตัวแปรและการนำตัวแปรมาคำนวณ แสดงดังรูป โดย cell ที่ 1 มีการประกาศตัวแปรชื่อ message, a และ b พร้อมกำหนดค่าเป็น "Hello World", 5 และ 2 ตามลำดับ หลังจากนั้นมีการใช้คำสั่ง print เพื่อแสดงผลข้อมูลในตัวแปร message ส่วน cell ที่ 2 มีการประกาศตัวแปรชื่อ result และมีการกำหนดค่าให้กับตัวแปรด้วยการนำตัวแปร a และ b มาบวกกัน โดยที่ตัวแปร a และ b ได้ถูกประกาศไว้ที่ cell ที่ 1 หลังจากนั้นมีการใช้คำสั่ง print เพื่อแสดงผลข้อมูลในตัวแปร result โดยถ้าผู้ใช้รันโค้ดใน cell ที่ 2 โดยไม่ได้รันโค้ดใน cell ที่ 1 จะทำให้เกิดข้อผิดพลาดขึ้นได้ เนื่องจากโค้ดใน cell ที่ 2 ต้องใช้ข้อมูลตัวแปรจากใน cell ที่ 1
เมื่อผู้ใช้สร้างไฟล์ในส่วนของ Analytic สำเร็จ ให้ผู้ใช้กลับไปที่ส่วนของ FlowEngine แล้ว double click โหนด "Jupyter Cell" ที่สร้างไว้ โดยที่หัวข้อ Filename ผู้ใช้สามารถพิมพ์ชื่อไฟล์ได้ หรือคลิกปุ่ม More vert หรือจุดสามจุด เพื่อแสดงรายการไฟล์ และเลือกไฟล์ที่ต้องการได้ แสดงดังรูป
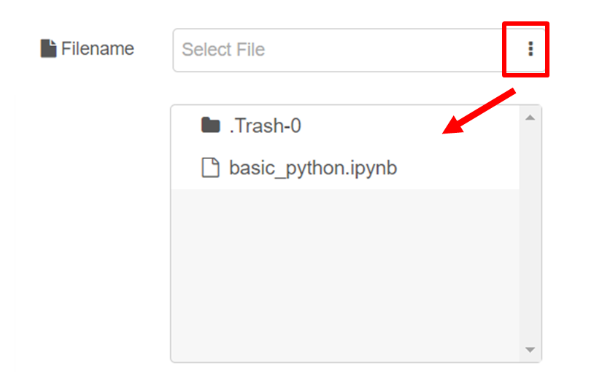
เมื่อผู้ใช้เลือกไฟล์ที่ต้องการแล้ว (เช่น /basic_python.jpynb) หัวข้อ Cell จะมีตัวเลือกเพิ่มขึ้นมา ซึ่งจะขึ้นอยู่กับจำนวน cell ที่ผู้ใช้สร้างไว้ในไฟล์ที่เลือก โดยจะมีหมายเลขกำกับไว้ที่แต่ละ cell ซึ่งหมายเลข 1 จะเริ่มต้นจาก cell ที่อยู่บนสุดของไฟล์ และเรียงลงมาตามลำดับ แสดงดังรูป
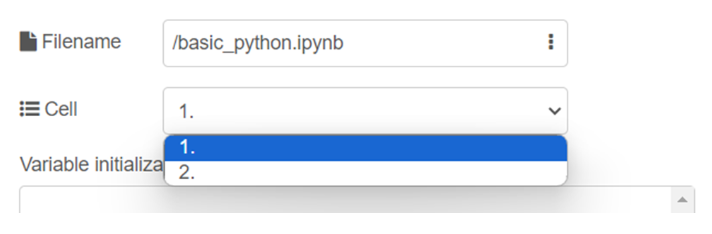
หมายเหตุ ตัวเลือกของ cell สามารถกำหนดชื่อเพิ่มเติมได้ โดยในบรรทัดแรกของ cell ให้ผู้ใช้พิมพ์ # แล้วตามด้วยชื่อที่ต้องการกำหนดให้ cell
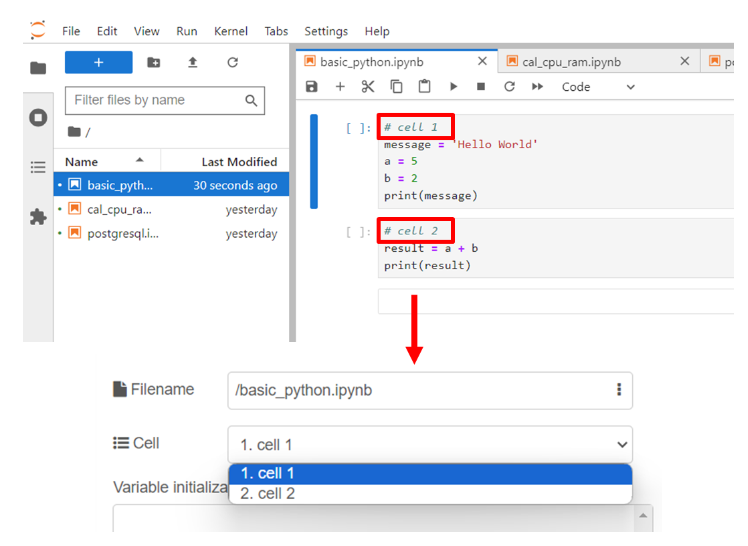
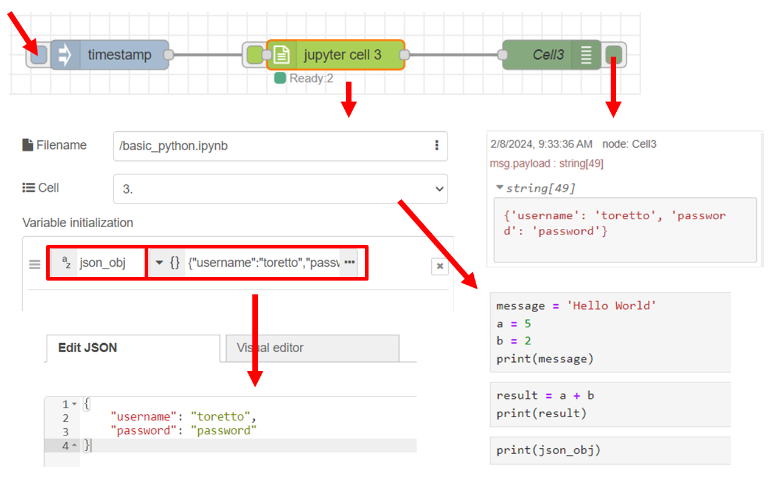
นอกจากนี้ผู้ใช้ยังสามารถสร้างตัวแปรผ่านโหนด "Jupyter Cell" แล้วนำตัวแปรไปใช้งานที่ส่วนของ Analytic ได้ ยกตัวอย่างเมื่อเลือก cell หมายเลข 2 โดยภายใน cell มีการนำตัวแปร a มาบวกกับตัวแปร b ซึ่งทั้งสองตัวแปรถูกประกาศไว้ที่ cell หมายเลข 1 ดังนั้นผู้ใช้สามารถสร้างตัวแปร a และตัวแปร b ได้จากหัวข้อ "Variable initialization" แสดงดังรูป
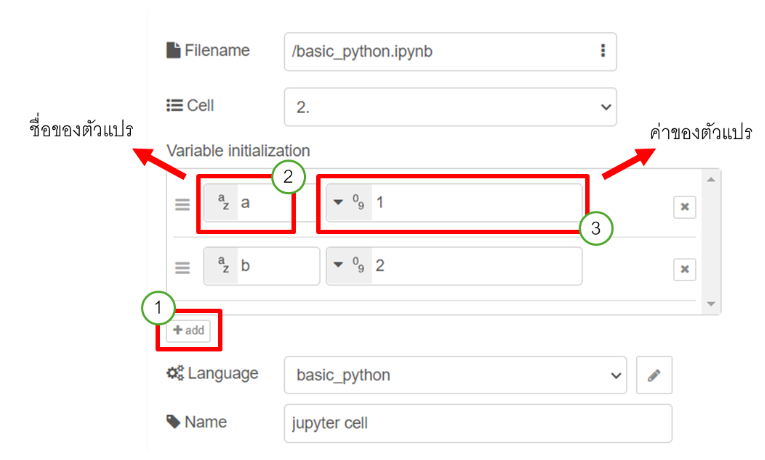
โดยโหนด "Jupyter Cell" รองรับการประกาศตัวแปรชนิด string (ข้อความ), number (ตัวเลข), boolean (true หรือ false) และ Object (อยู่ในรูปแบบ JSON) ดังรูป
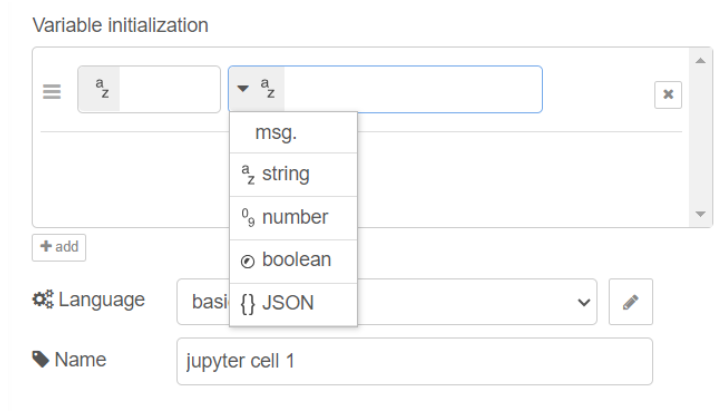
โหนด "Jupyter Cell" มี Input 1 ช่อง และมี Output 2 ช่อง โดย Input ใช้สำหรับการกระตุ้นให้โหนด "Jupyter Cell" ทำงาน ส่วน output มีทั้งหมด 2 ช่อง ดังนี้
text output เป็นข้อมูลทุกอย่างที่ฟังก์ชัน print ที่ส่วน Analytic แสดงผลออกมา
error output ข้อผิดพลาดที่เกิดจากการประมวลผล cell ที่เลือกของไฟล์นั้น

Text output ของโหนด "Jupyter cell" สามารถนำไปใช้ในการกระตุ้นโหนด "Jupyter cell" ถัดไปได้ ซึ่งจะสามารถนำไปกระตุ้นได้ก็ต่อเมื่อโหนด "Jupyter cell" นั้นรันโค้ดสำเร็จ ไม่มีข้อผิดพลาด โดยข้อมูลที่ออกมาจากช่อง output ทั้งหมด ถูกเก็บไว้ในตัวแปร msg.payload ซึ่งผู้ใช้สามารถเลือกโหนด debug มาใช้แสดงผลข้อมูลที่ debug message ได้ ยกตัวอย่างในข้อที่ 3 ทดลองรัน cell 1 ของไฟล์ basic_python.jpynb ซึ่งได้ผลลัพธ์ดังรูป
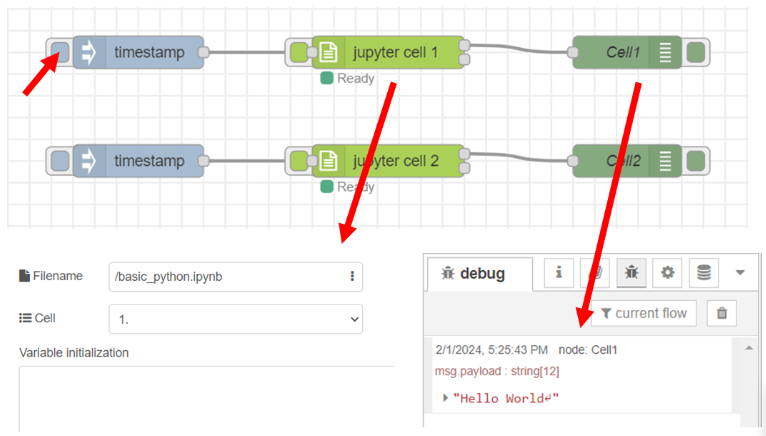
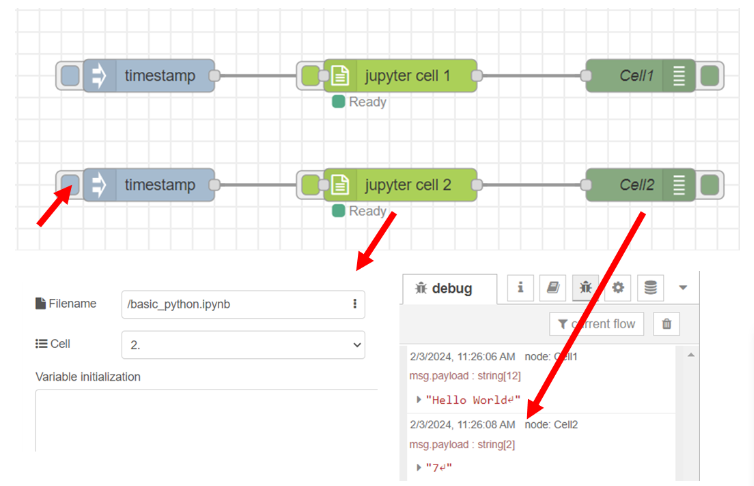
จากโค้ด python ใน cell หมายเลข 1 มีการใช้ฟังก์ชัน print เพื่อแสดงข้อมูลในตัวแปร message ซึ่งเป็นข้อความ "Hello World" โดย Output ของโหนด "Jupyter Cell" นำข้อความดังกล่าวที่ได้จากฟังก์ชัน print เก็บไว้ในตัวแปร msg.payload และหลังจากนั้นใช้โหนด Debug ที่ตั้งชื่อว่า "Cell1" นำข้อมูลจากตัวแปร msg.payload ไปแสดงที่ส่วน Debug นอกจากนี้โค้ด python ใน cell หมายเลข 1 ยังมีการประกาศตัวแปรชื่อ "a" และ "b" โดยจากตัวอย่างได้มีการนำข้อมูลตัวแปรดังกล่าวไปประมวลผลต่อที่ cell หมายเลข 2 ซึ่งถ้าทดลองรัน cell 2 ของไฟล์ basic_python.jpynb ต่อเนื่องจากการทดลองรัน cell 1 จะได้ผลลัพธ์ดังรูป
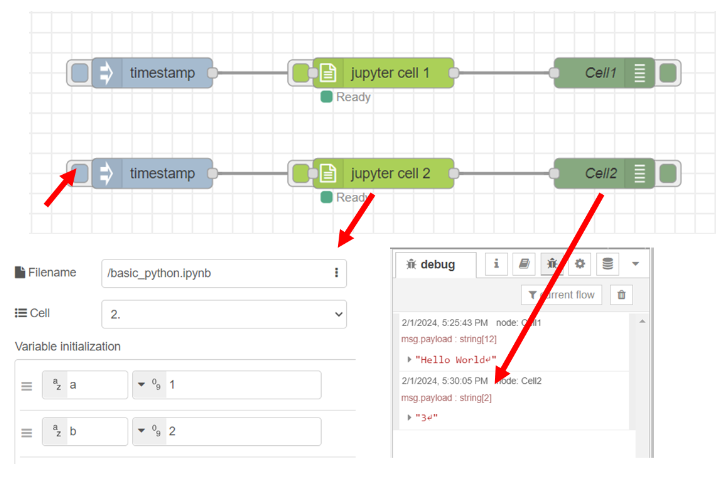
นอกจากนี้ถ้าทดลองประกาศตัวแปรที่ส่วนของ Variable initialization ของโหนด "Jupyter Cell" โดยให้ตั้งชื่อว่า "a" และ "b" ให้เท่ากับ 1 และ 2 ตามลำดับ ซึ่งเป็นทั้งสองตัวแปรมีชื่อเหมือนกับตัวแปร "a" และ "b" ที่ประกาศใน cell หมายเลข 1 ดังนั้นเมื่อทดลองรัน cell 2 จะได้ผลลัพธ์ที่แตกต่างออกไป เนื่องจากมีการกำหนดค่าให้กับตัวแปรใหม่ โดยผลลัพธ์เดิมคือ 7 แต่ผลลัพธ์ใหม่คือ 3 แสดงดังรูป
นอกจากการประกาศตัวแปรชนิด number แล้ว ผู้ใช้สามารถประกาศตัวแปรชนิดอื่นได้ เช่น การประกาศตัวแปรชนิด object ในรูปแบบ JSON ดังตัวอย่างในรูป
ตัวอย่าง
จากตัวอย่างจะเป็นการนำข้อมูลการใช้ของ CPU และ RAM ของเครื่องไปเก็บไว้ใน database postgresql ผ่าน library SQLalchemy บน Jupyter Notebook และนำข้อมูลจาก database ไปสร้างเป็นกราฟแสดงผลแบบ real-time บน grafana ที่มีอยู่ใน flow stack
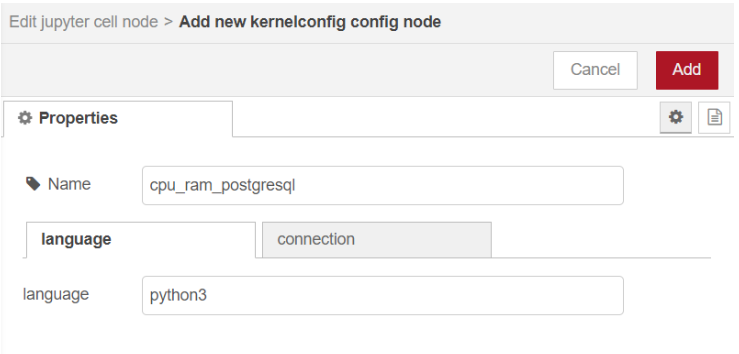
เริ่มต้นสร้าง language ใหม่ที่มีชื่อว่า "cpu_ram_postgresql" เพื่อใช้สำหรับตัวอย่างนี้ โดยกำหนด language เป็น "python3" และ connection เป็น "default" แสดงดังรูป
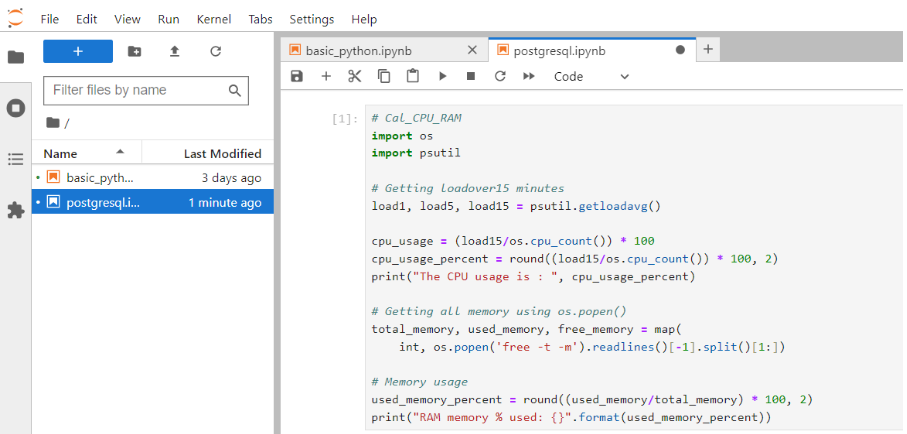
สร้างไฟล์ชื่อว่า "postgresql.ipynb" ที่ส่วนของ Analytic และเริ่มต้นสร้าง cell ที่ 1 ซึ่งเป็น cell ที่ทำหน้าที่ประมวลผลการใช้ CPU และ RAM โดยบรรทัดแรกของ cell ให้กำหนดเป็น comment "Cal_CPU_RAM" เพื่อเป็นชื่อ cell ซึ่งฝั่งโหนด "Jupyter Cell" จะเห็นเป็น "1. Cal_CPU_RAM" และข้อมูลการใช้ CPU และ RAM ที่ได้จะเก็บอยู่ในตัวแปร cpu_usage_percent และ used_memory_percent ตามลำดับ ผู้ใช้งานสามารถทดลองรัน cell นี้ที่ฝั่ง analytic ได้ด้วยการคลิก cell ที่ต้องการ แล้วกดปุ่ม shift+enter จะได้ผลลัพธ์แสดงดังรูป
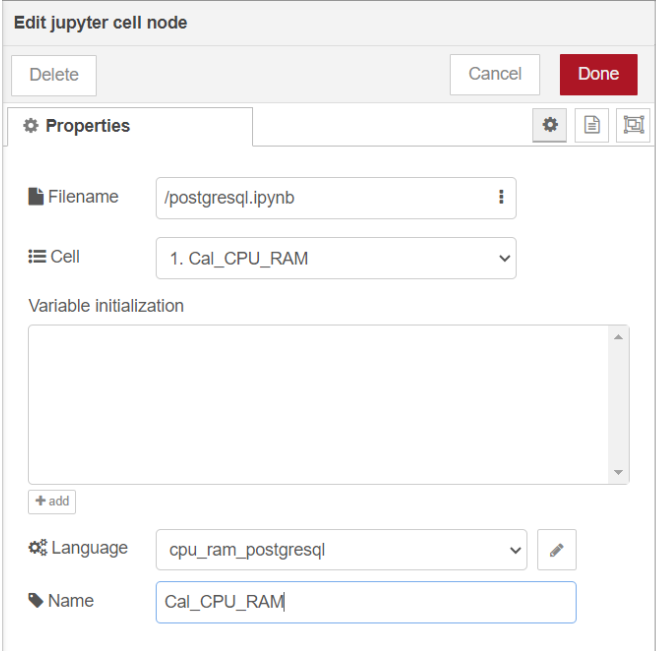
รัน cell "1. Cal_CPU_RAM" ที่โหนด "Jupyter Cell" ด้วยการใช้ language เป็น "cpu_ram_postgresql" ที่สร้างไว้ก่อนหน้านี้ โดยกำหนด Filename เป็น "postgresql.ipynb" และเลือก Cell ที่มีชื่อว่า "1. Cal_CPU_RAM" หลังจากนั้นเปลี่ยนชื่อของโหนดเป็น "Cal_CPU_RAM" เพื่อให้ง่ายต่อการใช้งานมากขึ้น ซึ่งแสดงดังรูป
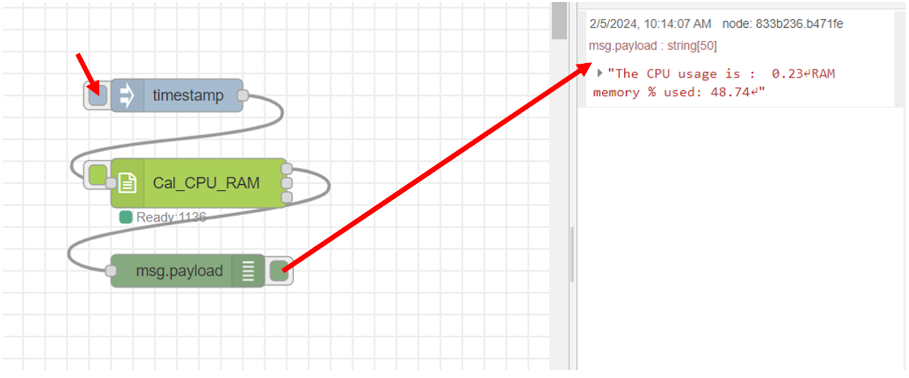
ลากโหนด "inject" และ "debug" มาเชื่อมต่อกับโหนด "Cal_CPU_RAM" โดยให้โหนด "inject" (โหนด "timestamp") เชื่อมต่อกับ input ของโหนด "Cal_CPU_RAM" และโหนด "debug" เชื่อมต่อกับ output ช่องที่ 1 ของ โหนด "Cal_CPU_RAM" ซึ่งเป็น text output โดยคลิก inject ที่โหนด "timestamp" หลังจากนั้นสังเกตผลลัพธ์ที่ส่วนของ debug โดยแสดงดังรูป
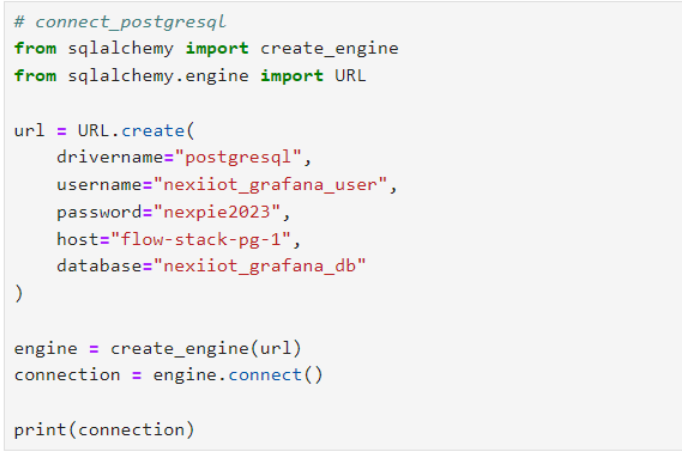
ขั้นตอนต่อมาเป็นส่วนของการสร้างการเชื่อมต่อกับ database postgresql ด้วย library SQLalchemy โดยเริ่มต้นสร้าง cell ที่ 2 ของไฟล์ "postgresql.ipynb" โดยบรรทัดแรกของ cell ให้กำหนดเป็น comment "connect_postgresql" เพื่อเกิดเป็นชื่อของ cell ซึ่งฝั่งโหนด "Jupyter Cell" จะเห็นเป็น "2. connect_postgresql" และเพิ่มโค้ดลงที่อยู่ในรูปลงใน cell โดยที่ก่อนที่ผู้ใช้จะใช้งาน cell นี้ได้ ผู้ใช้ต้องติดตั้ง library sqlalchemy เสียก่อน ซึ่งสามารถติดตั้งได้ด้วยคำสั่ง "!pip install SQLAlchemy" เมื่อผู้ใช้ติดตั้ง library สำเร็จแล้ว ทดลองรัน cell นี้ด้วยการคลิกที่ cell แล้วกดปุ่ม shift+enter จะได้ผลลัพธ์แสดงดังรูป
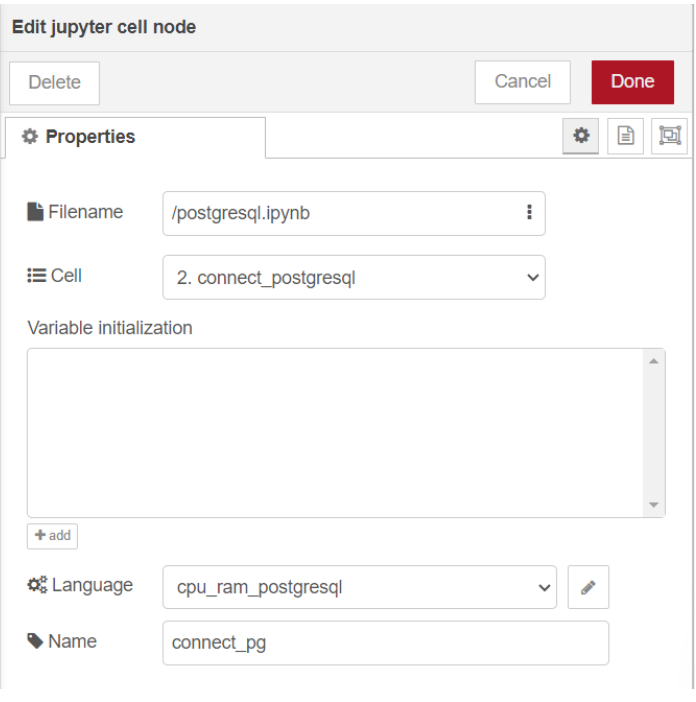
ทดลองรัน cell "2. connect_postgresql" ที่โหนด "Jupyter Cell" ด้วยการใช้ language เป็น "cpu_ram_postgresql" ที่สร้างไว้ก่อนหน้านี้ โดยกำหนด Filename เป็น "postgresql.ipynb" และเลือก Cell ที่มีชื่อว่า "2. connect_postgresql" หลังจากนั้นเปลี่ยนชื่อของโหนดเป็น "connect_pg" เพื่อให้ง่ายต่อการใช้งานมากขึ้น ซึ่งแสดงดังรูป
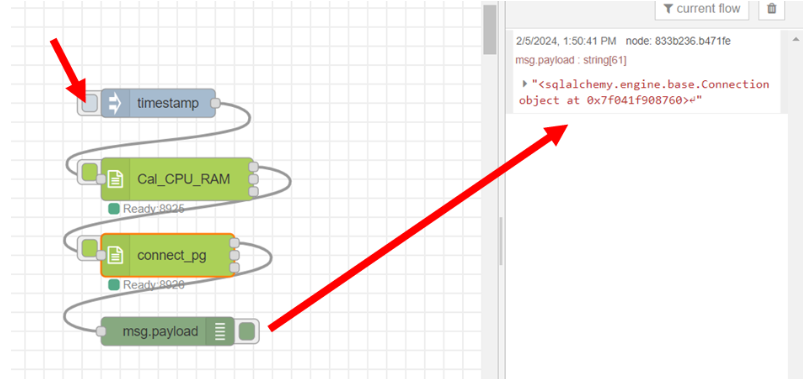
ลาก output ช่องที่ 3 ของโหนด "Cal_CPU_RAM" มาเชื่อมต่อกับ input ของโหนด "connect_pg" และ output ช่องที่ 1 ของ โหนด "connect_pg" เชื่อมต่อกับโหนด "debug" ซึ่งเป็น text output โดยคลิก inject ที่โหนด "timestamp" หลังจากนั้นสังเกตผลลัพธ์ที่ส่วนของ debug โดยแสดงดังรูป
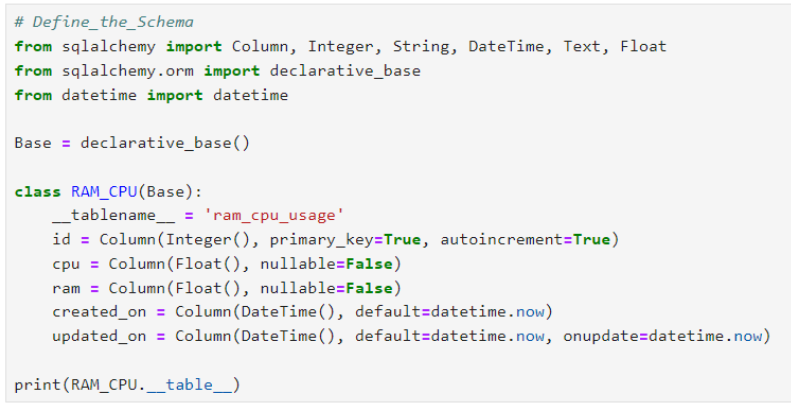
เมื่อสร้างการเชื่อมต่อกับ database สำเร็จแล้ว ขั้นตอนต่อมา คือ สร้าง schema สำหรับ Table ที่จะเก็บข้อมูลการใช้ CPU และ RAM ของเครื่อง โดยเริ่มต้นสร้าง cell ที่ 3 ของไฟล์ "postgresql.ipynb" โดยบรรทัดแรกของ cell ให้กำหนดเป็น comment "Define_the_Schema" เพื่อเกิดเป็นชื่อของ cell ซึ่งฝั่งโหนด "Jupyter Cell" จะเห็นเป็น "3. Define_the_Schema" และเพิ่มโค้ดลงที่อยู่ในรูปลงใน cell โดยตารางมีชื่อว่า "ram_cpu_usage" ประกอบด้วย column ดังนี้
id ลำดับของข้อมูล ชนิดข้อมูล interger
cpu ข้อมูลการใช้ cpu (หน่วยเป็น %) ชนิดข้อมูล float
ram ข้อมูลการใช้ ram (หน่วยเป็น %) ชนิดข้อมูล float
created_on เวลาที่สร้างข้อมูล ชนิดข้อมูล datetime
updated_on เวลาที่อัปเดตข้อมูล ชนิดข้อมูล datetime
แล้วทดลองรัน cell นี้ด้วยการคลิกที่ cell แล้วกดปุ่ม shift+enter จะได้ผลลัพธ์แสดงดังรูป
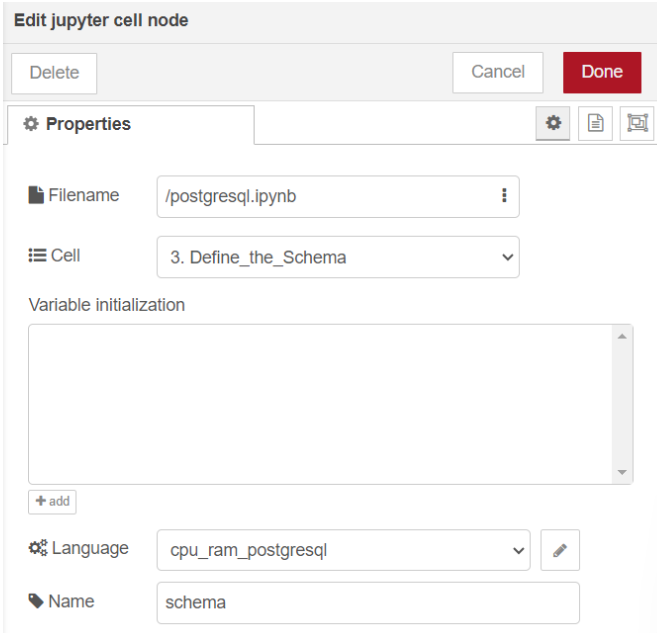
ทดลองรัน cell "3. Define_the_Schema" ที่โหนด "Jupyter Cell" ด้วยการใช้ language เป็น "cpu_ram_postgresql" ที่สร้างไว้ก่อนหน้านี้ โดยกำหนด Filename เป็น "postgresql.ipynb" และเลือก Cell ที่มีชื่อว่า "3. Define_the_Schema" หลังจากนั้นเปลี่ยนชื่อของโหนดเป็น "schema" เพื่อให้ง่ายต่อการใช้งานมากขึ้น ซึ่งแสดงดังรูป
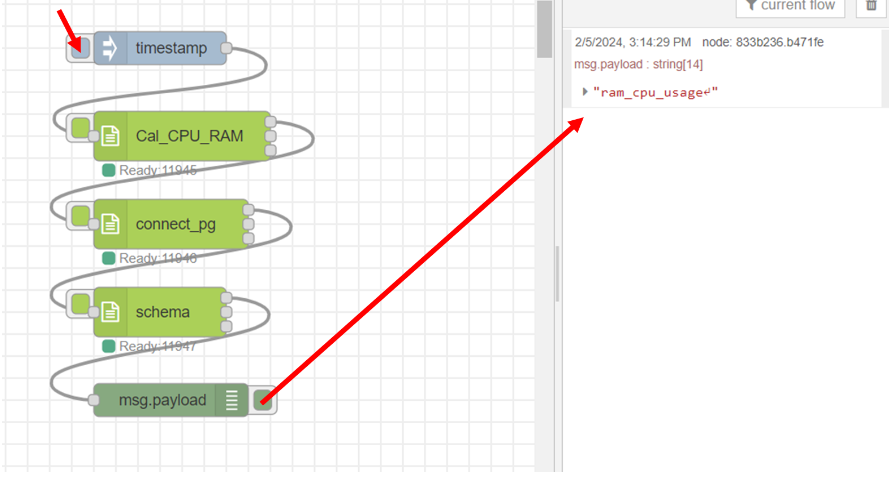
ลาก output ช่องที่ 3 ของโหนด "connect_pg" มาเชื่อมต่อกับ input ของโหนด "schema" และ output ช่องที่ 1 ของ โหนด "schema" เชื่อมต่อกับโหนด "debug" ซึ่งเป็น text output โดยคลิก inject ที่โหนด "timestamp" หลังจากนั้นสังเกตผลลัพธ์ที่ส่วนของ debug โดยแสดงดังรูป
เมื่อกำหนด schema สำหรับ Table สำเร็จ ขั้นตอนต่อมา คือ การทำให้ database มี Table ตรงกับที่ผู้ใช้กำหนดไว้ที่ schema หรือเรียกว่าการซิงค์ database โดยเริ่มต้นสร้าง cell ที่ 4 ของไฟล์ "postgresql.ipynb" โดยบรรทัดแรกของ cell ให้กำหนดเป็น comment "Sync_Database" เพื่อเกิดเป็นชื่อของ cell ซึ่งฝั่งโหนด "Jupyter Cell" จะเห็นเป็น "4. Sync_Database" และเพิ่มโค้ดลงที่อยู่ในรูปลงใน cell แล้วทดลองรัน cell นี้ด้วยการคลิกที่ cell แล้วกดปุ่ม shift+enter จะได้ผลลัพธ์แสดงดังรูป
ทดลองรัน cell "4. Sync_Database" ที่โหนด "Jupyter Cell" ด้วยการใช้ language เป็น "cpu_ram_postgresql" ที่สร้างไว้ก่อนหน้านี้ โดยกำหนด Filename เป็น "postgresql.ipynb" และเลือก Cell ที่มีชื่อว่า "4. Sync_Database" หลังจากนั้นเปลี่ยนชื่อของโหนดเป็น "sync_db" เพื่อให้ง่ายต่อการใช้งานมากขึ้น ซึ่งแสดงดังรูป
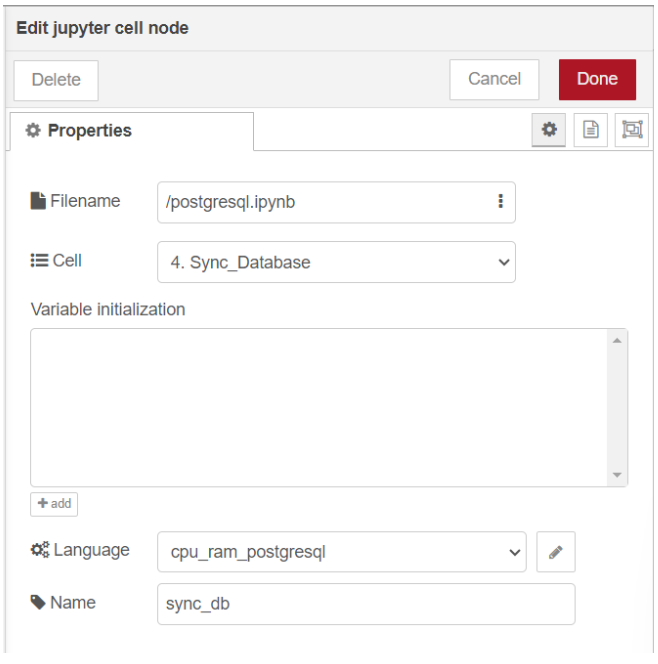
ลาก output ช่องที่ 3 ของโหนด "schema" มาเชื่อมต่อกับ input ของโหนด "sync_db" และ output ช่องที่ 1 ของ โหนด "sync_db" เชื่อมต่อกับโหนด "debug" ซึ่งเป็น text output โดยคลิก inject ที่โหนด "timestamp" หลังจากนั้นสังเกตผลลัพธ์ที่ส่วนของ debug โดยแสดงดังรูป
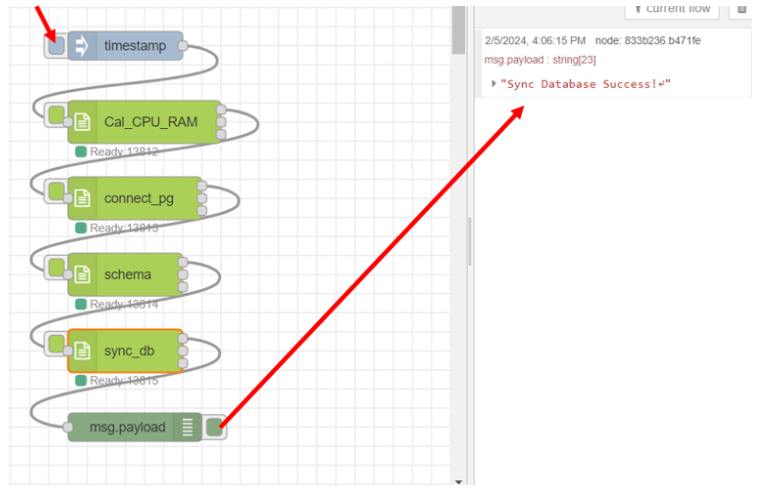
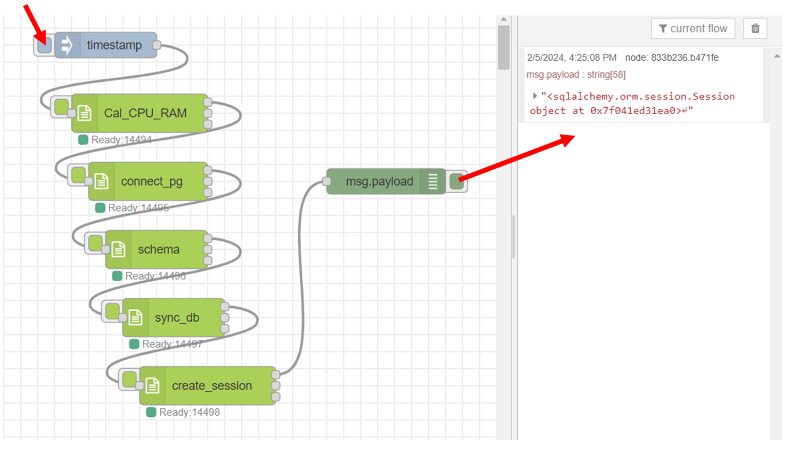
เมื่อทำการซิงค์ database สำเร็จ ขั้นตอนต่อมา คือ การสร้าง session เพื่อสื่อสารกับ database โดยเริ่มต้นสร้าง cell ที่ 5 ของไฟล์ "postgresql.ipynb" โดยบรรทัดแรกของ cell ให้กำหนดเป็น comment "Create_a_new_session" เพื่อเกิดเป็นชื่อของ cell ซึ่งฝั่งโหนด "Jupyter Cell" จะเห็นเป็น "5. Create_a_new_session" และเพิ่มโค้ดลงที่อยู่ในรูปลงใน cell แล้วทดลองรัน cell นี้ด้วยการคลิกที่ cell แล้วกดปุ่ม shift+enter จะได้ผลลัพธ์แสดงดังรูป
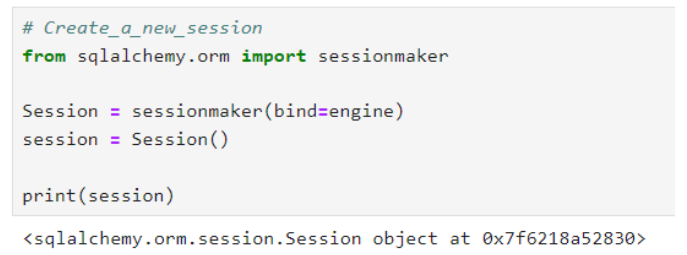
ทดลองรัน cell "5. Create_a_new_session" ที่โหนด "Jupyter Cell" ด้วยการใช้ language เป็น "cpu_ram_postgresql" ที่สร้างไว้ก่อนหน้านี้ โดยกำหนด Filename เป็น "postgresql.ipynb" และเลือก Cell ที่มีชื่อว่า "5. Create_a_new_session" หลังจากนั้นเปลี่ยนชื่อของโหนดเป็น "create_session" เพื่อให้ง่ายต่อการใช้งานมากขึ้น ซึ่งแสดงดังรูป
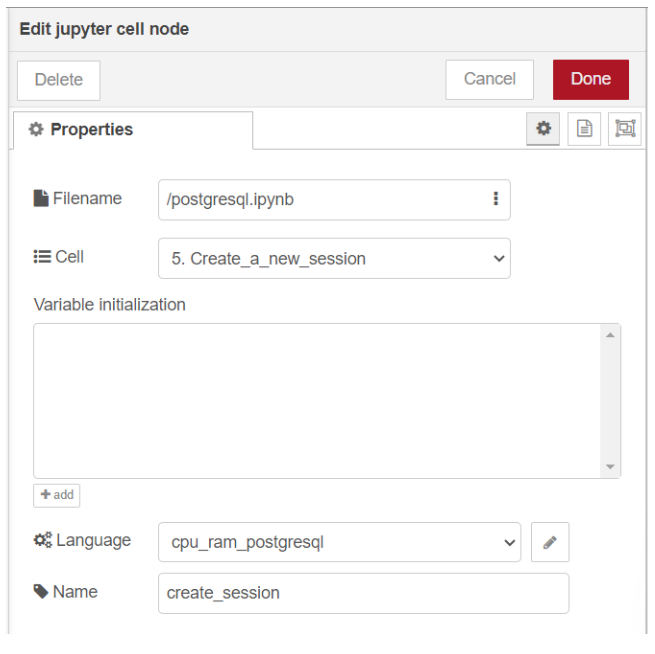
ลาก output ช่องที่ 3 ของโหนด "sync_db" มาเชื่อมต่อกับ input ของโหนด "create_session" และ output ช่องที่ 1 ของ โหนด "create_session" เชื่อมต่อกับโหนด "debug" ซึ่งเป็น text output โดยคลิก inject ที่โหนด "timestamp" หลังจากนั้นสังเกตผลลัพธ์ที่ส่วนของ debug โดยแสดงดังรูป
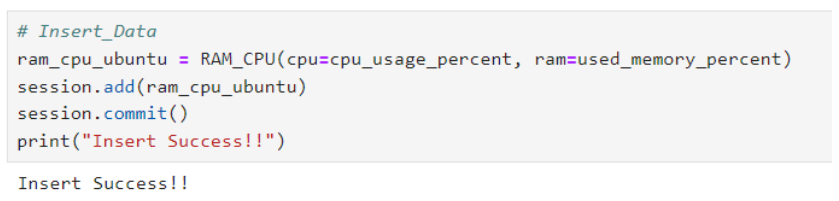
เมื่อสร้าง session สำเร็จ ผู้ใช้สามารถสร้างข้อมูล และเพิ่มข้อมูลลงใน database โดยเริ่มต้นสร้าง cell ที่ 6 ของไฟล์ "postgresql.ipynb" โดยบรรทัดแรกของ cell ให้กำหนดเป็น comment "Insert_Data" เพื่อเกิดเป็นชื่อของ cell ซึ่งฝั่งโหนด "Jupyter Cell" จะเห็นเป็น "6. Insert_Data" และเพิ่มโค้ดลงที่อยู่ในรูปลงใน cell แล้วทดลองรัน cell นี้ด้วยการคลิกที่ cell แล้วกดปุ่ม shift+enter จะได้ผลลัพธ์แสดงดังรูป
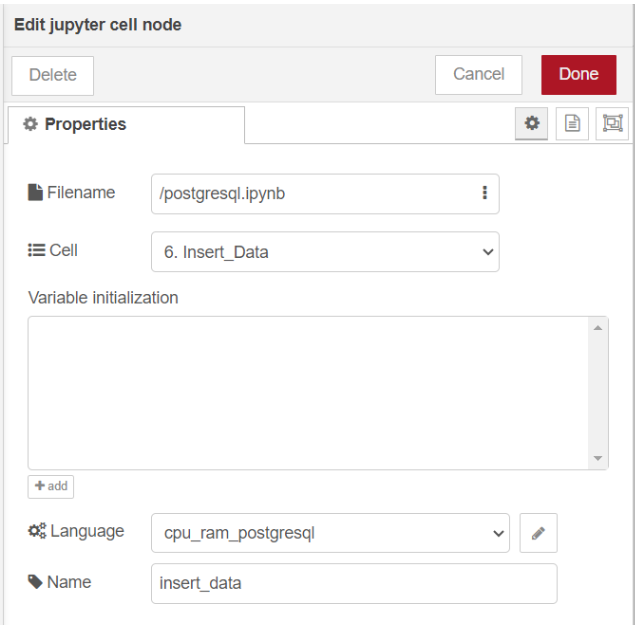
ทดลองรัน cell "6. Insert_Data" ที่โหนด "Jupyter Cell" ด้วยการใช้ language เป็น "cpu_ram_postgresql" ที่สร้างไว้ก่อนหน้านี้ โดยกำหนด Filename เป็น "postgresql.ipynb" และเลือก Cell ที่มีชื่อว่า "6. Insert_Data" หลังจากนั้นเปลี่ยนชื่อของโหนดเป็น "insert_data" เพื่อให้ง่ายต่อการใช้งานมากขึ้น ซึ่งแสดงดังรูป
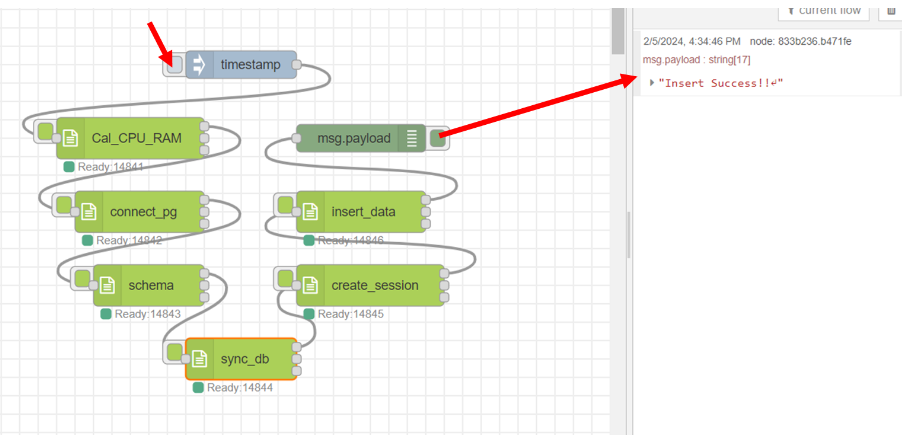
ลาก output ช่องที่ 3 ของโหนด "create_session" มาเชื่อมต่อกับ input ของโหนด "insert_data" และ output ช่องที่ 1 ของ โหนด "insert_data" เชื่อมต่อกับโหนด "debug" ซึ่งเป็น text output โดยคลิก inject ที่โหนด "timestamp" หลังจากนั้นสังเกตผลลัพธ์ที่ส่วนของ debug โดยแสดงดังรูป
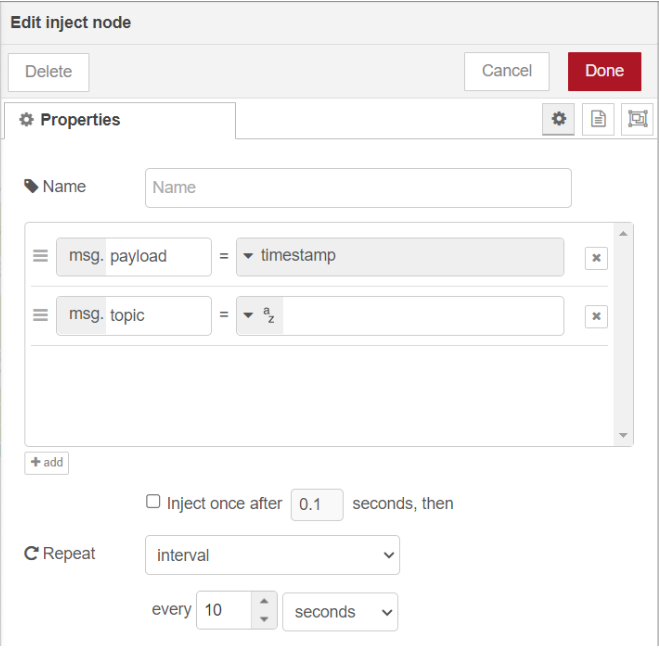
ก่อนที่ผู้ใช้จะไปสร้างกราฟแสดงผลบน Grafana ให้ผู้ใช้แก้ไขโหนด timestamp โดยกำหนดให้มีการทำซ้ำทุกๆ 10 วินาที ซึ่งแก้ไขที่หัวข้อ Repeat โดยเลือก interval และแก้ไขเวลาเป็น 10 แสดงดังรูป เพื่อให้โหนด "Jupyter Cell" ส่งข้อมูลไปเก็บใน database ทุกๆ 10 วินาที
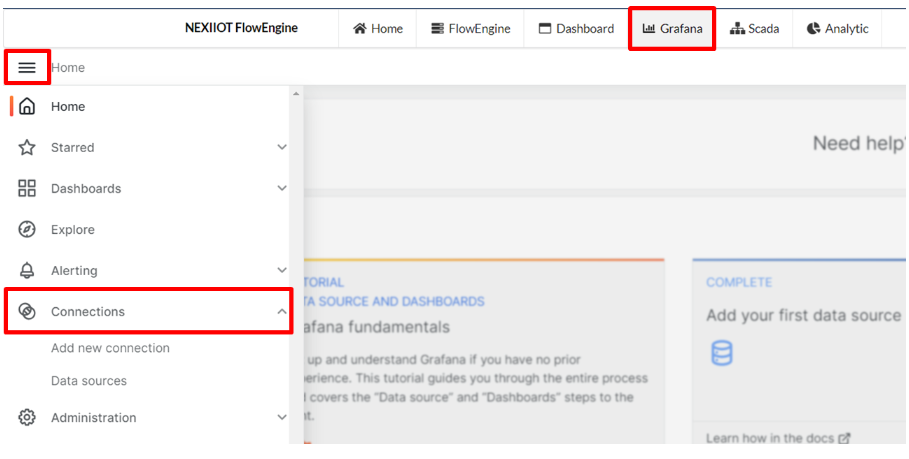
เมื่อผู้ใช้สามารถส่งข้อมูลไปยัง database ได้แล้ว ขั้นตอนต่อมาคือ การสร้างกราฟแสดงผลที่ Grafana โดยเริ่มต้นจากคลิก Grafana แล้วเลือกที่เมนู และคลิก "Connections" ดังรูป เพื่อสร้างการเชื่อมต่อระหว่าง database ที่ใช้งานกับ Grafana
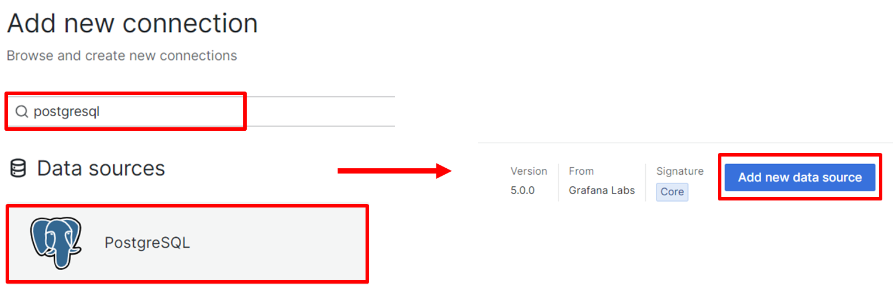
ขั้นตอนต่อมาคือค้นหา database โดยให้ผู้ใช้ค้นหา database ชื่อ "postgresql" แล้วเลือกที่ PostgreSQL หลังจากนั้นคลิก "Add new data source" ดังรูป
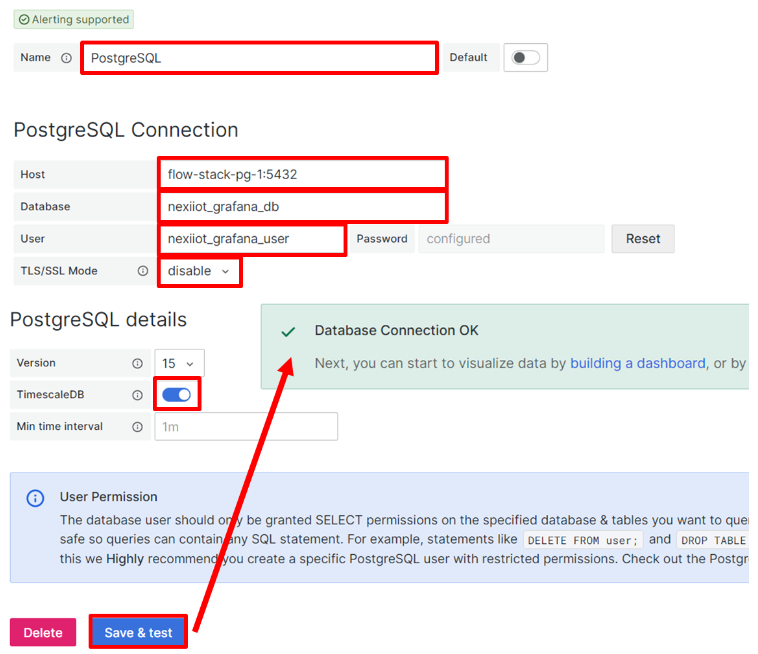
ขั้นตอนต่อมาคือกรอกรายละเอียดของ database ที่ต้องการเชื่อมต่อกับ grafana โดยให้ผู้ใช้กรอกรายละเอียดดังรูป ซึ่งข้อมูลต่างๆตรงกับข้อมูลที่ใช้ใน library SQLalchemy ที่ส่วนของ Analytic เมื่อผู้ใช้กรอกเสร็จแล้ว สามารถทดสอบการเชื่อมต่อได้ โดยกดปุ่ม Save & test ถ้าสำเร็จขึ้นข้อความ "Database Connection OK" ดังรูป
เมื่อสร้างการเชื่อมต่อกับ database สำเร็จแล้ว ขั้นตอนต่อมาคือการสร้าง dashboard โดยย้อนกลับไปคลิกที่ปุ่มเมนู แล้วเลือกหัวข้อ Dashboards หลังจากคลิกที่ New แล้วเลือก New dashboard จากนั้นจะขึ้นหน้าจอให้สร้าง dashboard ใหม่ โดยคลิกที่ปุ่ม Add visualization ดังรูป
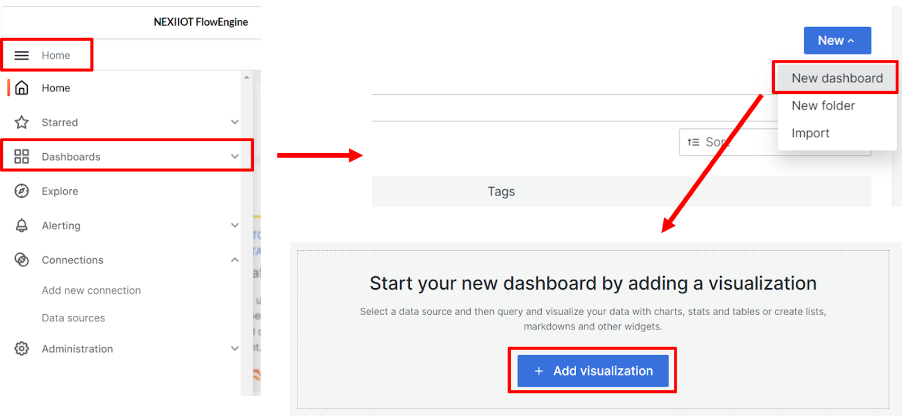
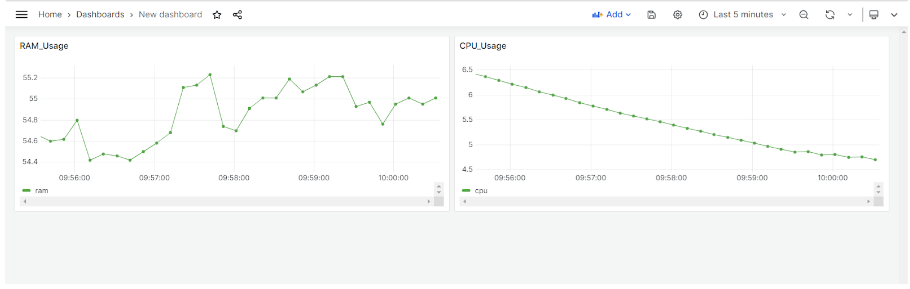
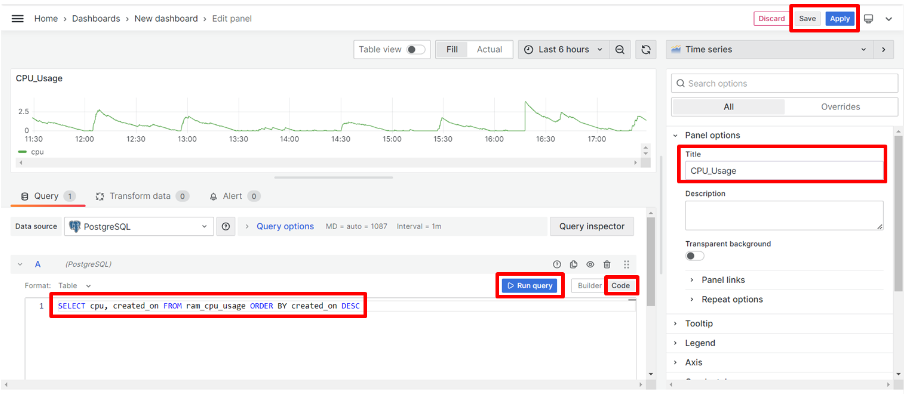
ดำเนินการเลือก connection ที่ต้องการ ซึ่งผู้ใช้ได้สร้าง connection ไว้แล้ว โดยมีชื่อว่า "PostgreSQL" ซึ่งให้ผู้ใช้คลิก "PostgreSQL" หลังจากนั้นจะขึ้นหน้าจอให้สร้างกราฟ โดยเริ่มต้นจากการสร้างกราฟการใช้ CPU โดยผู้ใช้สามารถตั้งค่ารายละเอียดต่างๆได้ดังรูป ซึ่งเป็นการดึงข้อมูลจาก column cpu และ created_on จากตาราง ram_cpu_usage นอกจากนี้มีการตั้งค่าชื่อของกราฟเป็น "CPU_Usage"
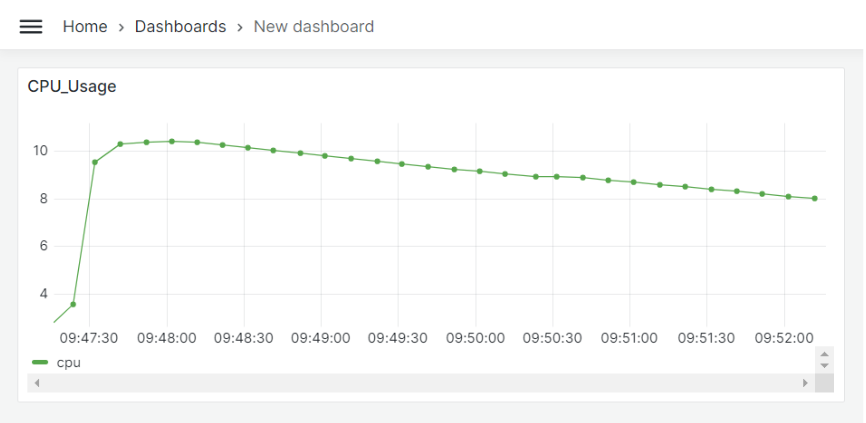
เมื่อตั้งค่ารายละเอียดต่างๆของ dashboard สำเร็จแล้ว จะได้ผลลัพธ์ดังรูป
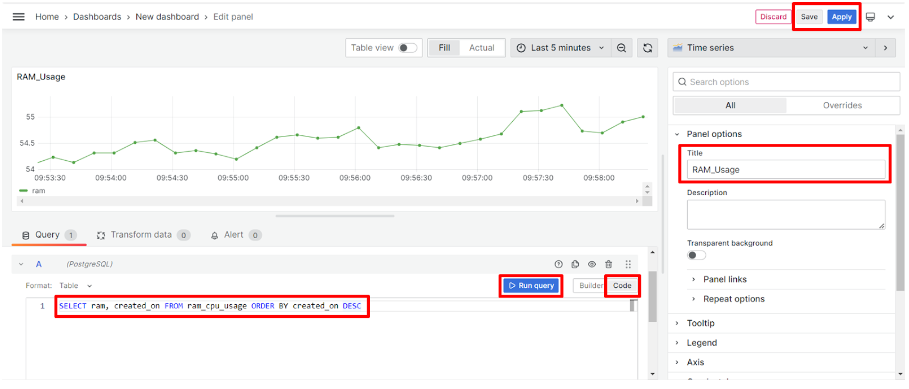
ขั้นตอนต่อมาเพิ่มกราฟการใช้ RAM ผู้ใช้สามารถตั้งค่ารายละเอียดต่างๆได้ดังรูป ซึ่งเป็นการดึงข้อมูลจาก column cpu และ created_on จากตาราง ram_cpu_usage นอกจากนี้มีการตั้งค่าชื่อของกราฟเป็น "CPU_Usage"
เมื่อเพิ่มกราฟการใช้ CPU และ RAM สำเร็จ ผู้ใช้จะได้ผลลัพธ์เป็นหน้า Dashboard ดังรูป